AZ-305: Azure Solutions Architect Expert
Topic 2: Data Storage Solutions - 전체 39문제 완벽 해설
✑ 저장 프로시저는 CLR을 사용하여 구현됩니다.
✑ 가장 큰 데이터베이스는 현재 3TB입니다. 어떤 데이터베이스도 4TB를 초과하지 않습니다.
모든 데이터를 SQL Server에서 Azure로 이동할 계획입니다.
데이터베이스를 호스팅할 서비스를 권장해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다:
✑ 가능한 한 마이그레이션된 데이터베이스의 관리 오버헤드를 최소화해야 합니다.
✑ 사용자가 Azure Active Directory(Azure AD) 자격 증명을 사용하여 인증할 수 있도록 해야 합니다.
✑ 마이그레이션을 용이하게 하는 데 필요한 데이터베이스 변경 수를 최소화해야 합니다.
권장 사항에 무엇을 포함해야 합니까?
정답: B - Azure SQL Managed Instance
정답 근거: Azure SQL Managed Instance는 온프레미스 SQL Server와 가장 높은 호환성을 제공하며, CLR 지원, Azure AD 인증, 최소한의 코드 변경으로 마이그레이션이 가능합니다.
상세 해설
핵심 요구사항 분석:
- CLR 저장 프로시저 지원: Common Language Runtime 기능이 필요
- 대용량 데이터베이스: 최대 4TB까지의 데이터베이스 크기
- 최소 관리 오버헤드: 관리형 서비스가 선호됨
- Azure AD 인증: 통합된 인증 시스템
- 최소 코드 변경: 호환성이 높은 솔루션
옵션별 분석:
- A. Azure SQL Database elastic pools: CLR을 지원하지 않음
- B. Azure SQL Managed Instance: ✅ CLR 지원, 높은 호환성, 관리형 서비스
- C. Azure SQL Database single: CLR을 지원하지 않음
- D. SQL Server on VM: 관리 오버헤드가 큼
Windows Server 2016을 실행하는 Server1이라는 온프레미스 파일 서버가 있습니다. Server1에는 500GB의 회사 파일이 저장되어 있습니다.
Server1의 회사 파일 복사본을 store1에 저장해야 합니다.
이 목표를 달성하는 두 가지 가능한 Azure 서비스는 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다.
참고: 각 올바른 선택은 1점의 가치가 있습니다.
정답: B, C - Azure Import/Export job & Azure Data Factory
정답 근거: 두 서비스 모두 온프레미스에서 Azure Blob Storage로 대용량 데이터를 전송할 수 있는 완전한 솔루션입니다.
상세 해설
요구사항:
- 온프레미스 서버(Server1)에서 500GB 파일을 Azure Blob Storage로 복사
- 완전한 솔루션을 제공하는 두 가지 방법
정답 분석:
- B. Azure Import/Export job: - 물리적 디스크를 Azure 데이터센터로 배송하여 대용량 데이터 전송 - 네트워크 대역폭 제한이 있는 경우 효과적 - 500GB 정도의 데이터에 적합
- C. Azure Data Factory: - 하이브리드 데이터 통합 서비스 - 온프레미스와 클라우드 간 데이터 이동 및 변환 - Self-hosted Integration Runtime을 통한 온프레미스 연결
오답 분석:
- A. Logic Apps: 워크플로 자동화용, 파일 복사에는 부적합
- D. Analysis Services Gateway: 분석 서비스용 게이트웨이
- E. Azure Batch: 대규모 병렬 컴퓨팅용, 파일 전송과는 무관
향후에는 트랜잭션의 특정 세부 정보를 기반으로 배송 요청의 일부를 처리할 추가 애플리케이션이 추가될 예정입니다.
각 추가 애플리케이션이 관련 트랜잭션을 읽을 수 있도록 스토리지 계정 큐를 대체할 솔루션을 권장해야 합니다.
무엇을 권장해야 합니까?
정답: D - one Azure Service Bus topic
정답 근거: Service Bus Topic은 여러 구독자(애플리케이션)가 동일한 메시지를 받을 수 있는 pub/sub 패턴을 지원합니다.
상세 해설
현재 상황:
- App1 → Storage Queue → App2 (1:1 관계)
- 향후 여러 애플리케이션이 동일한 메시지를 처리해야 함
- 각 애플리케이션은 특정 세부 정보를 기반으로 필터링
Storage Queue vs Service Bus 비교:
- Storage Queue: - 간단한 FIFO 큐 - 한 번 읽으면 메시지가 사라짐 (1:1 소비)
- Service Bus Queue: - 고급 큐잉 기능 - 여전히 1:1 소비 패턴
- Service Bus Topic: - Publish/Subscribe 패턴 - 여러 구독(subscription)을 통해 1:N 소비
Service Bus Topic의 장점:
- 다중 구독자: 여러 애플리케이션이 동일한 메시지 수신
- 필터링: 각 구독에서 SQL 필터나 상관관계 필터 사용
- 확장성: 새로운 애플리케이션 추가가 용이
- 메시지 중복: 각 구독자가 독립적으로 메시지 처리
자주 사용되는 대량의 데이터를 저장할 앱용 스토리지 솔루션을 설계해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다:
✑ 데이터 처리량을 최대화합니다.
✑ 1년 동안 데이터 수정을 방지합니다.
✑ 읽기 및 쓰기 작업의 대기 시간을 최소화합니다.
권장할 Azure Storage 계정 유형 및 스토리지 서비스는 무엇입니까?
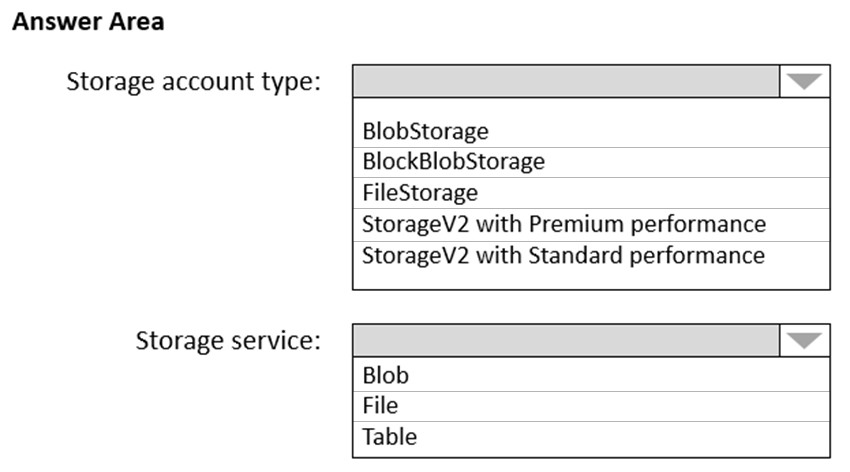
정답: B - BlockBlobStorage + Blob

정답 근거: BlockBlobStorage는 프리미엄 성능과 낮은 지연시간을 제공하며, Blob은 불변성(immutability) 정책을 지원합니다.
상세 해설
요구사항 분석:
- 최대 처리량: 높은 IOPS와 대역폭 필요
- 1년간 수정 방지: 불변성(Immutability) 정책 필요
- 최소 지연시간: 프리미엄 스토리지 성능 필요
- 자주 사용되는 데이터: Hot 액세스 계층
BlockBlobStorage의 특징:
- 프리미엄 성능: 낮은 지연시간과 높은 처리량
- Block Blob 전용: 대용량 파일과 스트리밍에 최적화
- 고성능 SSD: 일관된 성능 보장
- 불변성 지원: Legal Hold와 Time-based retention 정책
Blob 불변성 정책:
- Time-based retention: 지정된 기간 동안 수정/삭제 방지
- Legal Hold: 법적 요구사항을 위한 무기한 보호
- WORM (Write Once, Read Many): 한 번 쓰고 여러 번 읽기
다음 표에 표시된 스토리지 계정이 포함된 Azure 구독이 있습니다.
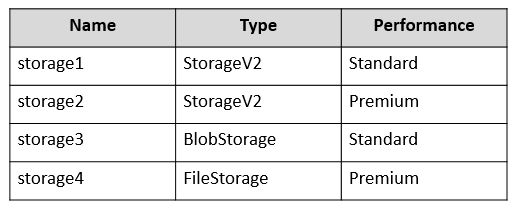
다음 표에 표시된 요구 사항이 있는 두 개의 새 앱을 구현할 계획입니다.

각 앱에 사용하도록 권장할 스토리지 계정은 무엇입니까?

정답
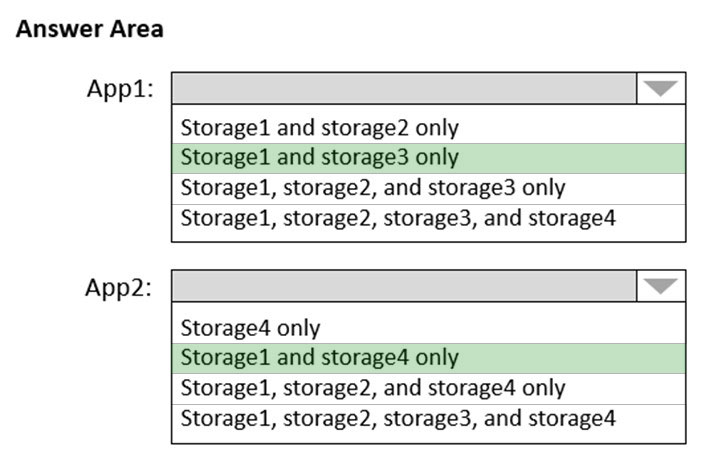
Standard 계정을 사용해야 합니다. 프리미엄 Block Blob 스토리지 계정에 저장된 데이터는 Set Blob Tier나 Azure Blob Storage 수명 주기 관리를 사용하여 핫, 쿨 또는 아카이브로 계층화할 수 없습니다.
Box 2: Storage1 and storage4 only
Azure 파일 공유에는 프리미엄 계정이 필요합니다. Storage1과 storage4만 프리미엄입니다.
상세 해설
App1 요구사항 분석:
- Blob 액세스 계층 변경: Hot/Cool/Archive 간 이동 필요
- Standard 계정만 가능: 프리미엄 Block Blob는 계층화 불가
- Storage1 (General Purpose v2): ✅ 모든 액세스 계층 지원
- Storage3 (General Purpose v2): ✅ 모든 액세스 계층 지원
App2 요구사항 분석:
- Azure Files 사용: 파일 공유 서비스
- 프리미엄 성능 필요: 고성능 파일 공유
- Storage1 (General Purpose v2, Premium): ✅ 프리미엄 파일 지원
- Storage4 (FileStorage, Premium): ✅ 파일 전용 프리미엄
스토리지 계정 유형별 특징:
- General Purpose v2: 모든 서비스, 모든 액세스 계층
- BlockBlobStorage: Block Blob만, 액세스 계층 변경 불가
- FileStorage: Azure Files만, 프리미엄 성능
애플리케이션은 50MB에서 12GB 범위의 비디오 파일을 호스팅합니다. 애플리케이션은 인증서 기반 인증을 사용하며 인터넷의 사용자가 사용할 수 있습니다.
비디오 파일의 스토리지 옵션을 권장해야 합니다. 솔루션은 가장 빠른 읽기 성능을 제공해야 하며 스토리지 비용을 최소화해야 합니다.
무엇을 권장해야 합니까?
정답: C - Azure Blob Storage
정답 근거: Azure Blob Storage는 비디오 파일과 같은 대용량 미디어 파일에 최적화되어 있으며, CDN과 통합하여 빠른 읽기 성능과 비용 효율성을 제공합니다.
상세 해설
요구사항 분석:
- 비디오 파일: 50MB ~ 12GB의 대용량 미디어 파일
- 인터넷 사용자: 공개적으로 액세스 가능
- 빠른 읽기 성능: 스트리밍에 적합한 성능
- 비용 최소화: 경제적인 스토리지 솔루션
Azure Blob Storage의 장점:
- 미디어 최적화: 비디오, 이미지 등 대용량 파일에 특화
- HTTP/HTTPS 액세스: 웹 애플리케이션에서 직접 액세스
- CDN 통합: 전 세계적으로 빠른 콘텐츠 배포
- 액세스 계층: Hot/Cool/Archive로 비용 최적화
- 대용량 지원: 최대 5PB까지 확장
다른 옵션 분석:
- A. Azure Files: 파일 공유용, 미디어 스트리밍에 부적합
- B. Data Lake Storage Gen2: 빅데이터 분석용, 과도한 기능
- D. Azure SQL Database: 관계형 데이터용, 미디어 파일에 부적합
데이터베이스를 호스팅할 데이터베이스 플랫폼을 권장해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다:
✑ 솔루션은 99.99% 가동 시간의 SLA(서비스 수준 계약)를 충족해야 합니다.
✑ 데이터베이스에 할당된 컴퓨팅 리소스는 동적으로 확장되어야 합니다.
✑ 솔루션에는 예약된 용량이 있어야 합니다.
컴퓨팅 요금을 최소화해야 합니다.

정답: A - an elastic pool that contains 20 Azure SQL databases
정답 근거: Elastic Pool은 다양한 사용 패턴을 가진 여러 데이터베이스의 리소스를 효율적으로 공유하여 비용을 최소화하면서 동적 확장과 높은 SLA를 제공합니다.
상세 해설
요구사항 분석:
- 20개 데이터베이스: 각 20GB, 다양한 사용 패턴
- 99.99% SLA: 높은 가용성 요구
- 동적 확장: 워크로드에 따른 자동 스케일링
- 예약 용량: 리소스 보장
- 비용 최소화: 경제적인 솔루션
Elastic Pool의 장점:
- 리소스 공유: 사용 패턴이 다른 DB들이 eDTU/vCore 공유
- 비용 효율성: 개별 DB보다 총 비용 절약
- 자동 스케일링: 풀 내에서 리소스 동적 할당
- 99.99% SLA: Microsoft가 보장하는 높은 가용성
- 예약 용량: 풀 수준에서 리소스 보장
다른 옵션 비교:
- B/C. SQL Server on VM: 관리 오버헤드 높음, 99.99% SLA 달성 어려움
- D. SQL Database Serverless: 개별 DB 관리로 비용 비효율적
Azure로 마이그레이션할 온프레미스 데이터베이스가 있습니다.
다음 요구 사항을 충족하는 데이터베이스 아키텍처를 설계해야 합니다:
✑ 확장 및 축소를 지원합니다.
✑ 지역 중복 백업을 지원합니다.
✑ 최대 75TB의 데이터베이스를 지원합니다.
✑ OLTP(온라인 트랜잭션 처리)에 최적화되어야 합니다.
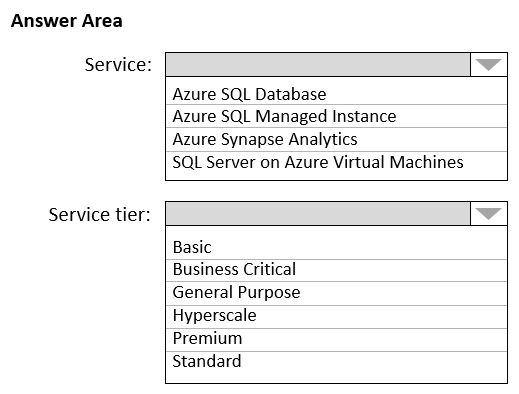
정답
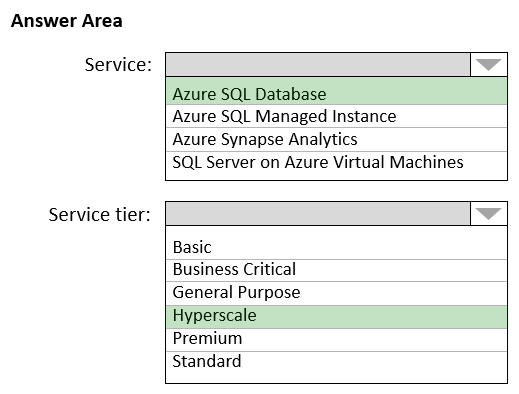
Azure SQL Database는 Hyperscale 서비스 계층 모델로 최대 100TB까지의 데이터베이스를 지원합니다. 활성 지역 복제는 주 데이터베이스에 대해 지속적으로 동기화된 읽기 가능한 보조 데이터베이스를 만들 수 있는 기능입니다.
Box 2: Hyperscale
Azure SQL Database와 SQL Managed Instance를 사용하면 최소한의 가동 중지 시간으로 데이터베이스에 더 많은 리소스를 동적으로 추가할 수 있습니다.
상세 해설
요구사항 분석:
- 75TB 지원: 대용량 데이터베이스 요구사항
- OLTP 최적화: 온라인 트랜잭션 처리 성능
- 확장성: Scale up/down 지원
- 지역 중복 백업: 재해 복구 기능
Azure SQL Database Hyperscale 특징:
- 대용량 지원: 최대 100TB까지 확장 가능
- 빠른 스케일링: 스토리지는 자동, 컴퓨팅은 동적 확장
- 다층 아키텍처: 컴퓨팅, 로그, 스토리지 분리
- 백업 및 복원: 스냅샷 기반 빠른 백업
- 지역 복제: 활성 지역 복제 지원
다른 옵션과의 비교:
- SQL Server on VM: 지역 복제 미지원
- Azure Synapse Analytics: OLAP 최적화, OLTP에 부적합
- SQL Managed Instance: 최대 16TB 제한
DB1과 DB2를 Azure로 마이그레이션할 계획입니다.
DB1과 DB2를 호스팅할 Azure 솔루션을 권장해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다:
✑ DB1과 DB2에서 서버 측 트랜잭션을 지원합니다.
✑ 솔루션을 업데이트하는 관리 노력을 최소화합니다.
무엇을 권장해야 합니까?
정답: B - two databases on the same Azure SQL managed instance
정답 근거: Azure SQL Managed Instance는 동일한 인스턴스 내의 데이터베이스 간 분산 트랜잭션을 지원하며, 최소한의 관리 오버헤드를 제공합니다.
상세 해설
핵심 요구사항:
- 서버 측 트랜잭션: DB1과 DB2 간의 분산 트랜잭션
- 최소 관리 노력: 관리형 서비스 선호
분산 트랜잭션 지원 비교:
- Azure SQL Database: - 동일한 서버 내에서도 크로스 DB 트랜잭션 미지원 - Elastic Query는 읽기 전용
- Azure SQL Managed Instance: - 동일한 인스턴스 내 데이터베이스 간 분산 트랜잭션 완전 지원 - SQL Server와 거의 100% 호환성
- SQL Server on VM: - 분산 트랜잭션 지원하지만 관리 오버헤드 높음
Azure SQL Managed Instance의 장점:
- 크로스 DB 트랜잭션: BEGIN DISTRIBUTED TRANSACTION 지원
- 관리형 서비스: 패치, 백업, 모니터링 자동화
- 높은 호환성: 온프레미스에서 최소 변경으로 마이그레이션
- VNet 통합: 기업 네트워크와 완전 통합
✑ 데이터베이스 복제본 간 장애 조치는 데이터 손실 없이 발생해야 합니다.
✑ 영역 중단 시에도 데이터베이스가 사용 가능해야 합니다.
✑ 비용을 최소화해야 합니다.
어떤 배포 옵션을 사용해야 합니까?
정답: B - Azure SQL Database Premium
정답 근거: Premium 계층은 영역 중복성(Zone Redundancy)을 지원하여 영역 중단 시에도 데이터 손실 없이 자동 장애 조치가 가능합니다.
상세 해설
요구사항 분석:
- 데이터 손실 없는 장애조치: RPO = 0
- 영역 중단 대응: Zone Redundancy 필요
- 비용 최소화: 요구사항을 만족하는 최소 계층
Azure SQL Database 계층별 고가용성:
- Basic/Standard: - 로컬 중복 스토리지만 - 영역 중복성 미지원
- Premium/Business Critical: - Always On 가용성 그룹 - 영역 중복성 옵션 제공 - 동기식 복제로 데이터 손실 없음
- Hyperscale: - 고성능이지만 영역 중복성 제한적 - Premium보다 비용 높음
Premium 계층의 영역 중복성:
- 3개 복제본: 서로 다른 가용성 영역에 배치
- 동기식 복제: 커밋 전 모든 복제본에 쓰기
- 자동 장애조치: 수초 내 투명한 장애조치
- 99.995% SLA: 영역 중복성 활성화 시
민감한 데이터용 Azure Storage 솔루션을 계획하고 있습니다. 데이터는 매일 액세스됩니다. 데이터 세트는 10GB 미만입니다.
다음 요구 사항을 충족하는 스토리지 솔루션을 권장해야 합니다:
✑ 스토리지에 기록된 모든 데이터는 5년간 보존되어야 합니다.
✑ 데이터가 기록되면 읽기만 가능합니다. 수정 및 삭제는 방지되어야 합니다.
✑ 5년 후에는 데이터를 삭제할 수 있지만 수정은 절대 불가능합니다.
✑ 데이터 액세스 요금을 최소화해야 합니다.

정답

Box 2: Legal hold - 5년간 수정/삭제 방지 후 삭제만 허용하려면 Legal hold 정책이 필요합니다.
상세 해설
액세스 계층 선택:
- 매일 액세스: 자주 사용되는 데이터
- Hot 계층: 액세스 비용 최소, 높은 스토리지 비용
- 10GB 미만: 스토리지 비용보다 액세스 비용이 중요
불변성 정책 비교:
- Time-based retention: - 고정된 보존 기간 - 기간 만료 후 자동 삭제 가능
- Legal hold: - 수동 해제까지 보호 - 보다 엄격한 보호 - 5년 후 수동으로 해제하여 삭제 허용
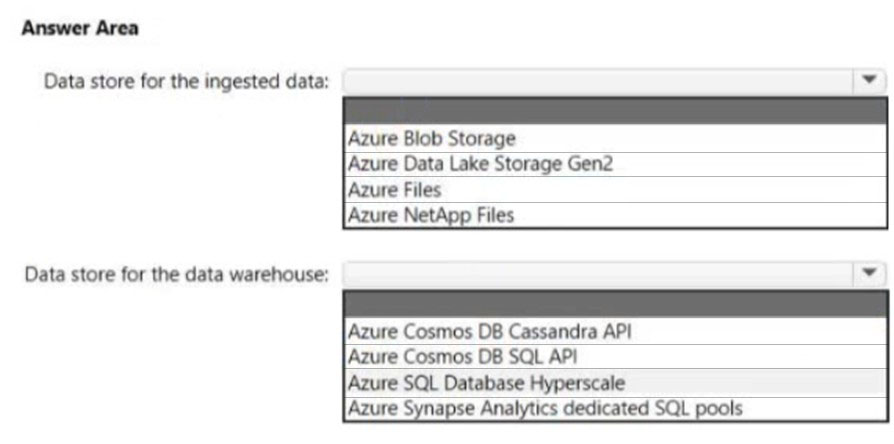
보고를 지원하는 데이터 스토리지 솔루션을 설계하고 있습니다.
솔루션은 Azure Event Hubs를 사용하여 JSON 형식의 대용량 데이터를 수집합니다. 데이터가 도착하면 Event Hubs가 데이터를 스토리지에 씁니다. 솔루션은 다음 요구 사항을 충족해야 합니다:
✑ 데이터를 날짜 및 시간별로 디렉터리에 구성합니다.
✑ 저장된 데이터를 직접 쿼리하고, 요약 테이블로 변환한 다음 데이터 웨어하우스에 저장할 수 있도록 허용합니다.
✑ 데이터 웨어하우스가 50TB의 관계형 데이터를 저장하고 200~300개의 동시 읽기 작업을 지원할 수 있도록 보장합니다.
정답
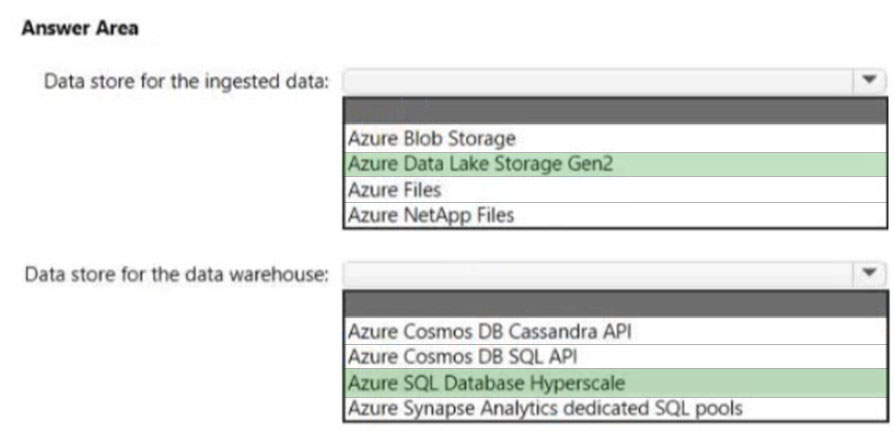
Box 2: Azure SQL Database Hyperscale - 최대 100TB까지 지원하며 높은 동시성과 성능을 제공합니다.
상세 해설
Data Lake Storage Gen2 선택 이유:
- 계층적 네임스페이스: 날짜/시간별 폴더 구조
- 빅데이터 최적화: 대용량 JSON 데이터 처리
- Event Hubs 통합: 네이티브 연결 지원
- 분석 도구 지원: 직접 쿼리 가능
Hyperscale vs Synapse 비교:
- Hyperscale: - 최대 100TB - OLTP 최적화 - 높은 동시성 (200-300 세션)
- Synapse Analytics: - 최대 240TB - OLAP 최적화 - 동시 쿼리 제한 (128개)
DB1을 Azure SQL 관리형 인스턴스로 마이그레이션할 계획입니다.
인스턴스에 대해 고객 관리 TDE(투명한 데이터 암호화)를 활성화해야 합니다. 솔루션은 암호화 강도를 최대화해야 합니다.
TDE 보호기에 어떤 유형의 암호화 알고리즘과 키 길이를 사용해야 합니까?
정답: A - RSA 3072
정답 근거: Azure SQL Managed Instance에서 고객 관리 TDE에 지원되는 최대 RSA 키 길이는 3072비트입니다.
상세 해설
Azure SQL MI TDE 지원 키:
- RSA 2048: 최소 지원 길이
- RSA 3072: 최대 지원 길이 (정답)
- RSA 4096: SQL MI에서 미지원
- AES 256: 대칭키, TDE 보호기에 부적합
TDE 작동 방식:
- DEK (Database Encryption Key): AES 256으로 실제 암호화
- TDE 보호기: DEK를 암호화하는 비대칭 키
- Key Vault 저장: RSA 키를 Azure Key Vault에 보관
각 장치는 온도, 장치 ID, 시간 데이터를 포함한 데이터를 스트리밍합니다. 약 50,000개의 레코드가 매초마다 기록됩니다. 데이터는 거의 실시간으로 시각화됩니다.
데이터를 저장하고 쿼리할 서비스를 권장해야 합니다.
권장할 수 있는 두 가지 서비스는 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다.
정답: C, D - Azure Cosmos DB for NoSQL & Azure Time Series Insights
정답 근거: 이는 문제 9와 동일한 시나리오로, 두 서비스 모두 고처리량 IoT 데이터에 최적화되어 있습니다.
상세 해설
동일한 솔루션이 적용되는 이유:
- 동일한 요구사항: 50,000 장치, 초당 50,000 레코드
- 실시간 시각화: 낮은 지연시간 필요
- 시계열 데이터: 온도, 시간 기반 데이터






















